前端面试题--性能优化篇

一、CDN
1. CDN的概念
CDN(Content Delivery Network,内容分发网络)是指一种通过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。
典型的CDN系统由下面三个部分组成:
- 分发服务系统:最基本的工作单元就是Cache设备,cache(边缘cache)负责直接响应最终用户的访问请求,把缓存在本地的内容快速地提供给用户。同时cache还负责与源站点进行内容同步,把更新的内容以及本地没有的内容从源站点获取并保存在本地。Cache设备的数量、规模、总服务能力是衡量一个CDN系统服务能力的最基本的指标。
- 负载均衡系统:主要功能是负责对所有发起服务请求的用户进行访问调度,确定提供给用户的最终实际访问地址。两级调度体系分为全局负载均衡(GSLB)和本地负载均衡(SLB)。全局负载均衡主要根据用户就近性原则,通过对每个服务节点进行“最优”判断,确定向用户提供服务的cache的物理位置。本地负载均衡主要负责节点内部的设备负载均衡
- 运营管理系统:运营管理系统分为运营管理和网络管理子系统,负责处理业务层面的与外界系统交互所必须的收集、整理、交付工作,包含客户管理、产品管理、计费管理、统计分析等功能。
2. CDN的作用
CDN一般会用来托管Web资源(包括文本、图片和脚本等),可供下载的资源(媒体文件、软件、文档等),应用程序(门户网站等)。使用CDN来加速这些资源的访问。
(1)在性能方面,引入CDN的作用在于:
- 用户收到的内容来自最近的数据中心,延迟更低,内容加载更快
- 部分资源请求分配给了CDN,减少了服务器的负载
(2)在安全方面,CDN有助于防御DDoS、MITM等网络攻击:
- 针对DDoS:通过监控分析异常流量,限制其请求频率
- 针对MITM:从源服务器到 CDN 节点到 ISP(Internet Service Provider),全链路 HTTPS 通信
除此之外,CDN作为一种基础的云服务,同样具有资源托管、按需扩展(能够应对流量高峰)等方面的优势。
3. CDN的原理
CDN和DNS有着密不可分的联系,先来看一下DNS的解析域名过程,在浏览器输入 www.test.com 的解析过程如下:
(1) 检查浏览器缓存
(2)检查操作系统缓存,常见的如hosts文件
(3)检查路由器缓存
(4)如果前几步都没没找到,会向ISP(网络服务提供商)的LDNS服务器查询
(5)如果LDNS服务器没找到,会向根域名服务器(Root Server)请求解析,分为以下几步:
- 根服务器返回顶级域名(TLD)服务器如
.com,.cn,.org等的地址,该例子中会返回.com的地址 - 接着向顶级域名服务器发送请求,然后会返回次级域名(SLD)服务器的地址,本例子会返回
.test的地址 - 接着向次级域名服务器发送请求,然后会返回通过域名查询到的目标IP,本例子会返回
www.test.com的地址 - Local DNS Server会缓存结果,并返回给用户,缓存在系统中
CDN的工作原理:
(1)用户未使用CDN缓存资源的过程:
- 浏览器通过DNS对域名进行解析(就是上面的DNS解析过程),依次得到此域名对应的IP地址
- 浏览器根据得到的IP地址,向域名的服务主机发送数据请求
- 服务器向浏览器返回响应数据
(2)用户使用CDN缓存资源的过程:
- 对于点击的数据的URL,经过本地DNS系统的解析,发现该URL对应的是一个CDN专用的DNS服务器,DNS系统就会将域名解析权交给CNAME指向的CDN专用的DNS服务器。
- CDN专用DNS服务器将CND的全局负载均衡设备IP地址返回给用户
- 用户向CDN的全局负载均衡设备发起数据请求
- CDN的全局负载均衡设备根据用户的IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求
- 区域负载均衡设备选择一台合适的缓存服务器来提供服务,将该缓存服务器的IP地址返回给全局负载均衡设备
- 全局负载均衡设备把服务器的IP地址返回给用户
- 用户向该缓存服务器发起请求,缓存服务器响应用户的请求,将用户所需内容发送至用户终端。
如果缓存服务器没有用户想要的内容,那么缓存服务器就会向它的上一级缓存服务器请求内容,以此类推,直到获取到需要的资源。最后如果还是没有,就会回到自己的服务器去获取资源。

CNAME(意为:别名):在域名解析中,实际上解析出来的指定域名对应的IP地址,或者该域名的一个CNAME,然后再根据这个CNAME来查找对应的IP地址。
4. CDN的使用场景
- 使用第三方的CDN服务:如果想要开源一些项目,可以使用第三方的CDN服务
- 使用CDN进行静态资源的缓存:将自己网站的静态资源放在CDN上,比如js、css、图片等。可以将整个项目放在CDN上,完成一键部署。
- 直播传送:直播本质上是使用流媒体进行传送,CDN也是支持流媒体传送的,所以直播完全可以使用CDN来提高访问速度。CDN在处理流媒体的时候与处理普通静态文件有所不同,普通文件如果在边缘节点没有找到的话,就会去上一层接着寻找,但是流媒体本身数据量就非常大,如果使用回源的方式,必然会带来性能问题,所以流媒体一般采用的都是主动推送的方式来进行。
二、懒加载
1. 懒加载的概念
懒加载也叫做延迟加载、按需加载,指的是在长网页中延迟加载图片数据,是一种较好的网页性能优化的方式。在比较长的网页或应用中,如果图片很多,所有的图片都被加载出来,而用户只能看到可视窗口的那一部分图片数据,这样就浪费了性能。
如果使用图片的懒加载就可以解决以上问题。在滚动屏幕之前,可视化区域之外的图片不会进行加载,在滚动屏幕时才加载。这样使得网页的加载速度更快,减少了服务器的负载。懒加载适用于图片较多,页面列表较长(长列表)的场景中。
2. 懒加载的特点
- 减少无用资源的加载:使用懒加载明显减少了服务器的压力和流量,同时也减小了浏览器的负担。
- 提升用户体验: 如果同时加载较多图片,可能需要等待的时间较长,这样影响了用户体验,而使用懒加载就能大大的提高用户体验。
- 防止加载过多图片而影响其他资源文件的加载 :会影响网站应用的正常使用。
3. 懒加载的实现原理
图片的加载是由src引起的,当对src赋值时,浏览器就会请求图片资源。根据这个原理,我们使用HTML5 的data-xxx属性来储存图片的路径,在需要加载图片的时候,将data-xxx中图片的路径赋值给src,这样就实现了图片的按需加载,即懒加载。
注意:data-xxx 中的xxx可以自定义,这里我们使用data-src来定义。
懒加载的实现重点在于确定用户需要加载哪张图片,在浏览器中,可视区域内的资源就是用户需要的资源。所以当图片出现在可视区域时,获取图片的真实地址并赋值给图片即可。
使用原生JavaScript实现懒加载:
知识点:
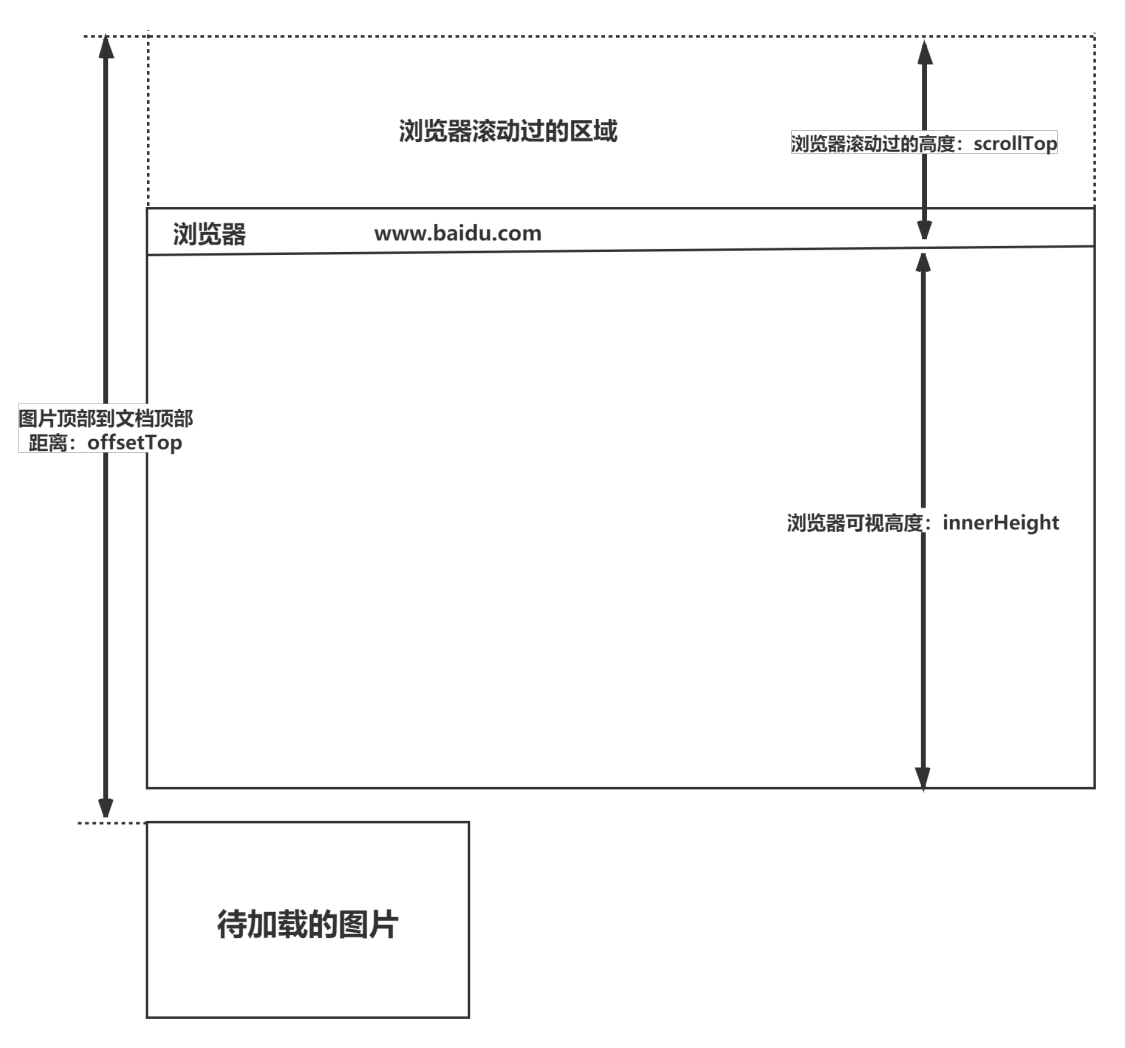
(1)window.innerHeight 是浏览器可视区的高度
(2)document.body.scrollTop || document.documentElement.scrollTop 是浏览器滚动的过的距离
(3)imgs.offsetTop 是元素顶部距离文档顶部的高度(包括滚动条的距离)
(4)图片加载条件:img.offsetTop < window.innerHeight + document.body.scrollTop;
图示:
代码实现:
1 | |
4. 懒加载与预加载的区别
这两种方式都是提高网页性能的方式,两者主要区别是一个是提前加载,一个是迟缓甚至不加载。懒加载对服务器前端有一定的缓解压力作用,预加载则会增加服务器前端压力。
- 懒加载也叫延迟加载,指的是在长网页中延迟加载图片的时机,当用户需要访问时,再去加载,这样可以提高网站的首屏加载速度,提升用户的体验,并且可以减少服务器的压力。它适用于图片很多,页面很长的电商网站的场景。懒加载的实现原理是,将页面上的图片的 src 属性设置为空字符串,将图片的真实路径保存在一个自定义属性中,当页面滚动的时候,进行判断,如果图片进入页面可视区域内,则从自定义属性中取出真实路径赋值给图片的 src 属性,以此来实现图片的延迟加载。
- 预加载指的是将所需的资源提前请求加载到本地,这样后面在需要用到时就直接从缓存取资源。通过预加载能够减少用户的等待时间,提高用户的体验。我了解的预加载的最常用的方式是使用 js 中的 image 对象,通过为 image 对象来设置 scr 属性,来实现图片的预加载。
三、回流与重绘
1. 回流与重绘的概念及触发条件
(1)回流
当渲染树中部分或者全部元素的尺寸、结构或者属性发生变化时,浏览器会重新渲染部分或者全部文档的过程就称为回流。
下面这些操作会导致回流:
- 页面的首次渲染
- 浏览器的窗口大小发生变化
- 元素的内容发生变化
- 元素的尺寸或者位置发生变化
- 元素的字体大小发生变化
- 激活CSS伪类
- 查询某些属性或者调用某些方法
- 添加或者删除可见的DOM元素
在触发回流(重排)的时候,由于浏览器渲染页面是基于流式布局的,所以当触发回流时,会导致周围的DOM元素重新排列,它的影响范围有两种:
- 全局范围:从根节点开始,对整个渲染树进行重新布局
- 局部范围:对渲染树的某部分或者一个渲染对象进行重新布局
(2)重绘
当页面中某些元素的样式发生变化,但是不会影响其在文档流中的位置时,浏览器就会对元素进行重新绘制,这个过程就是重绘。
下面这些操作会导致重绘:
- color、background 相关属性:background-color、background-image 等
- outline 相关属性:outline-color、outline-width 、text-decoration
- border-radius、visibility、box-shadow
注意: 当触发回流时,一定会触发重绘,但是重绘不一定会引发回流。
2. 如何避免回流与重绘?
减少回流与重绘的措施:
- 操作DOM时,尽量在低层级的DOM节点进行操作
- 不要使用
table布局, 一个小的改动可能会使整个table进行重新布局 - 使用CSS的表达式
- 不要频繁操作元素的样式,对于静态页面,可以修改类名,而不是样式。
- 使用absolute或者fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
- 避免频繁操作DOM,可以创建一个文档片段
documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中 - 将元素先设置
display: none,操作结束后再把它显示出来。因为在display属性为none的元素上进行的DOM操作不会引发回流和重绘。 - 将DOM的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机制。
浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列
浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。
上面,将多个读操作(或者写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。
3. 如何优化动画?
对于如何优化动画,我们知道,一般情况下,动画需要频繁的操作DOM,就就会导致页面的性能问题,我们可以将动画的position属性设置为absolute或者fixed,将动画脱离文档流,这样他的回流就不会影响到页面了。
4. documentFragment 是什么?用它跟直接操作 DOM 的区别是什么?
MDN中对documentFragment的解释:
DocumentFragment,文档片段接口,一个没有父对象的最小文档对象。它被作为一个轻量版的 Document使用,就像标准的document一样,存储由节点(nodes)组成的文档结构。与document相比,最大的区别是DocumentFragment不是真实 DOM 树的一部分,它的变化不会触发 DOM 树的重新渲染,且不会导致性能等问题。
当我们把一个 DocumentFragment 节点插入文档树时,插入的不是 DocumentFragment 自身,而是它的所有子孙节点。在频繁的DOM操作时,我们就可以将DOM元素插入DocumentFragment,之后一次性的将所有的子孙节点插入文档中。和直接操作DOM相比,将DocumentFragment 节点插入DOM树时,发一次重新渲染(因为所有的节点会被一次插入到文档中,而这个操作仅发生一个重渲染的操作,而不是每个节点分别被插入到文档中,因为后者会发生多次重渲染的操作),这样就大大提高了页面的性能。
四、节流与防抖
1. 对节流与防抖的理解
- 函数防抖是指在事件被触发 n 秒后再执行回调,如果在这 n 秒内事件又被触发,则重新计时。这可以使用在一些点击请求的事件上,避免因为用户的多次点击向后端发送多次请求。
- 函数节流是指规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。节流可以使用在 scroll 函数的事件监听上,通过事件节流来降低事件调用的频率。
防抖函数的应用场景:
- 按钮提交场景:防⽌多次提交按钮,只执⾏最后提交的⼀次
- 服务端验证场景:表单验证需要服务端配合,只执⾏⼀段连续的输⼊事件的最后⼀次,还有搜索联想词功能类似⽣存环境请⽤lodash.debounce
节流函数的适⽤场景:
- 拖拽场景:固定时间内只执⾏⼀次,防⽌超⾼频次触发位置变动
- 缩放场景:监控浏览器resize
- 动画场景:避免短时间内多次触发动画引起性能问题
2. 实现节流函数和防抖函数
函数防抖的实现:
1 | |
函数节流的实现:
1 | |
五、图片优化
1. 如何对项目中的图片进行优化?
- 不用图片。很多时候会使用到很多修饰类图片,其实这类修饰图片完全可以用 CSS 去代替。
- 对于移动端来说,屏幕宽度就那么点,完全没有必要去加载原图浪费带宽。一般图片都用 CDN 加载,可以计算出适配屏幕的宽度,然后去请求相应裁剪好的图片。
- 小图使用 base64 格式
- 将多个图标文件整合到一张图片中(雪碧图)
- 选择正确的图片格式:
- 对于能够显示 WebP 格式的浏览器尽量使用 WebP 格式。因为 WebP 格式具有更好的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量,缺点就是兼容性并不好
- 小图使用 PNG,其实对于大部分图标这类图片,完全可以使用 SVG 代替
- 照片使用 JPEG
2. 常见的图片格式及使用场景
(1)BMP,是无损的、既支持索引色也支持直接色的点阵图。这种图片格式几乎没有对数据进行压缩,所以BMP格式的图片通常是较大的文件。
(2)GIF是无损的、采用索引色的点阵图。采用LZW压缩算法进行编码。文件小,是GIF格式的优点,同时,GIF格式还具有支持动画以及透明的优点。但是GIF格式仅支持8bit的索引色,所以GIF格式适用于对色彩要求不高同时需要文件体积较小的场景。
(3)JPEG是有损的、采用直接色的点阵图。JPEG的图片的优点是采用了直接色,得益于更丰富的色彩,JPEG非常适合用来存储照片,与GIF相比,JPEG不适合用来存储企业Logo、线框类的图。因为有损压缩会导致图片模糊,而直接色的选用,又会导致图片文件较GIF更大。
(4)PNG-8是无损的、使用索引色的点阵图。PNG是一种比较新的图片格式,PNG-8是非常好的GIF格式替代者,在可能的情况下,应该尽可能的使用PNG-8而不是GIF,因为在相同的图片效果下,PNG-8具有更小的文件体积。除此之外,PNG-8还支持透明度的调节,而GIF并不支持。除非需要动画的支持,否则没有理由使用GIF而不是PNG-8。
(5)PNG-24是无损的、使用直接色的点阵图。PNG-24的优点在于它压缩了图片的数据,使得同样效果的图片,PNG-24格式的文件大小要比BMP小得多。当然,PNG24的图片还是要比JPEG、GIF、PNG-8大得多。
(6)SVG是无损的矢量图。SVG是矢量图意味着SVG图片由直线和曲线以及绘制它们的方法组成。当放大SVG图片时,看到的还是线和曲线,而不会出现像素点。这意味着SVG图片在放大时,不会失真,所以它非常适合用来绘制Logo、Icon等。
(7)WebP是谷歌开发的一种新图片格式,WebP是同时支持有损和无损压缩的、使用直接色的点阵图。从名字就可以看出来它是为Web而生的,什么叫为Web而生呢?就是说相同质量的图片,WebP具有更小的文件体积。现在网站上充满了大量的图片,如果能够降低每一个图片的文件大小,那么将大大减少浏览器和服务器之间的数据传输量,进而降低访问延迟,提升访问体验。目前只有Chrome浏览器和Opera浏览器支持WebP格式,兼容性不太好。
- 在无损压缩的情况下,相同质量的WebP图片,文件大小要比PNG小26%;
- 在有损压缩的情况下,具有相同图片精度的WebP图片,文件大小要比JPEG小25%~34%;
- WebP图片格式支持图片透明度,一个无损压缩的WebP图片,如果要支持透明度只需要22%的格外文件大小。
六、Webpack优化
1. 如何提⾼webpack的打包速度?
(1)优化 Loader
对于 Loader 来说,影响打包效率首当其冲必属 Babel 了。因为 Babel 会将代码转为字符串生成 AST,然后对 AST 继续进行转变最后再生成新的代码,项目越大,转换代码越多,效率就越低。当然了,这是可以优化的。
首先我们优化 Loader 的文件搜索范围
1 | |
对于 Babel 来说,希望只作用在 JS 代码上的,然后 node_modules 中使用的代码都是编译过的,所以完全没有必要再去处理一遍。
当然这样做还不够,还可以将 Babel 编译过的文件缓存起来,下次只需要编译更改过的代码文件即可,这样可以大幅度加快打包时间
1 | |
(2)HappyPack
受限于 Node 是单线程运行的,所以 Webpack 在打包的过程中也是单线程的,特别是在执行 Loader 的时候,长时间编译的任务很多,这样就会导致等待的情况。
HappyPack 可以将 Loader 的同步执行转换为并行的,这样就能充分利用系统资源来加快打包效率了
1 | |
(3)DllPlugin
DllPlugin 可以将特定的类库提前打包然后引入。DLL(Dynamic Link Library)文件为动态链接库文件。这种方式可以极大的减少打包类库的次数,只有当类库更新版本才有需要重新打包,并且也实现了将公共代码抽离成单独文件的优化方案。DllPlugin的使用方法如下:
1 | |
然后需要执行这个配置文件生成依赖文件,接下来需要使用 DllReferencePlugin 将依赖文件引入项目中
1 | |
(4)代码压缩
在 Webpack3 中,一般使用 UglifyJS 来压缩代码,但是这个是单线程运行的,为了加快效率,可以使用 webpack-parallel-uglify-plugin 来并行运行 UglifyJS,从而提高效率。
在 Webpack4 中,不需要以上这些操作了,只需要将 mode 设置为 production 就可以默认开启以上功能。代码压缩也是我们必做的性能优化方案,当然我们不止可以压缩 JS 代码,还可以压缩 HTML、CSS 代码,并且在压缩 JS 代码的过程中,我们还可以通过配置实现比如删除 console.log 这类代码的功能。
(5)其他
可以通过一些小的优化点来加快打包速度
resolve.extensions:用来表明文件后缀列表,默认查找顺序是['.js', '.json'],如果你的导入文件没有添加后缀就会按照这个顺序查找文件。我们应该尽可能减少后缀列表长度,然后将出现频率高的后缀排在前面resolve.alias:可以通过别名的方式来映射一个路径,能让 Webpack 更快找到路径module.noParse:如果你确定一个文件下没有其他依赖,就可以使用该属性让 Webpack 不扫描该文件,这种方式对于大型的类库很有帮助
2. 如何减少 Webpack 打包体积
(1)按需加载
在开发 SPA 项目的时候,项目中都会存在很多路由页面。如果将这些页面全部打包进一个 JS 文件的话,虽然将多个请求合并了,但是同样也加载了很多并不需要的代码,耗费了更长的时间。那么为了首页能更快地呈现给用户,希望首页能加载的文件体积越小越好,这时候就可以使用按需加载,将每个路由页面单独打包为一个文件。当然不仅仅路由可以按需加载,对于 loadash 这种大型类库同样可以使用这个功能。
按需加载的代码实现这里就不详细展开了,因为鉴于用的框架不同,实现起来都是不一样的。当然了,虽然他们的用法可能不同,但是底层的机制都是一样的。都是当使用的时候再去下载对应文件,返回一个 Promise,当 Promise 成功以后去执行回调。
(2)Scope Hoisting
Scope Hoisting 会分析出模块之间的依赖关系,尽可能的把打包出来的模块合并到一个函数中去。
比如希望打包两个文件:
1 | |
对于这种情况,打包出来的代码会类似这样:
1 | |
但是如果使用 Scope Hoisting ,代码就会尽可能的合并到一个函数中去,也就变成了这样的类似代码:
1 | |
这样的打包方式生成的代码明显比之前的少多了。如果在 Webpack4 中你希望开启这个功能,只需要启用 optimization.concatenateModules 就可以了:
1 | |
(3)Tree Shaking
Tree Shaking 可以实现删除项目中未被引用的代码,比如:
1 | |
对于以上情况,test 文件中的变量 b 如果没有在项目中使用到的话,就不会被打包到文件中。
如果使用 Webpack 4 的话,开启生产环境就会自动启动这个优化功能。
3. 如何⽤webpack来优化前端性能?
⽤webpack优化前端性能是指优化webpack的输出结果,让打包的最终结果在浏览器运⾏快速⾼效。
- 压缩代码:删除多余的代码、注释、简化代码的写法等等⽅式。可以利⽤webpack的 UglifyJsPlugin 和 ParallelUglifyPlugin 来压缩JS⽂件, 利⽤ cssnano (css-loader?minimize)来压缩css
- 利⽤CDN加速: 在构建过程中,将引⽤的静态资源路径修改为CDN上对应的路径。可以利⽤webpack对于 output 参数和各loader的 publicPath 参数来修改资源路径
- Tree Shaking: 将代码中永远不会⾛到的⽚段删除掉。可以通过在启动webpack时追加参数 –optimize-minimize 来实现
- Code Splitting: 将代码按路由维度或者组件分块(chunk),这样做到按需加载,同时可以充分利⽤浏览器缓存
- 提取公共第三⽅库: SplitChunksPlugin插件来进⾏公共模块抽取,利⽤浏览器缓存可以⻓期缓存这些⽆需频繁变动的公共代码
4. 如何提⾼webpack的构建速度?
- 多⼊⼝情况下,使⽤ CommonsChunkPlugin 来提取公共代码
- 通过 externals 配置来提取常⽤库
- 利⽤ DllPlugin 和 DllReferencePlugin 预编译资源模块 通过 DllPlugin 来对那些我们引⽤但是绝对不会修改的npm包来进⾏预编译,再通过 DllReferencePlugin 将预编译的模块加载进来。
- 使⽤ Happypack 实现多线程加速编译
- 使⽤ webpack-uglify-parallel 来提升 uglifyPlugin 的压缩速度。 原理上 webpack-uglify-parallel 采⽤了多核并⾏压缩来提升压缩速度
- 使⽤ Tree-shaking 和 Scope Hoisting 来剔除多余代码
七、性能优化的指标?用了哪些手段
https://juejin.cn/post/7026907443250593805
Web 指标是 Google 开创的一项新计划,旨在为网络质量信号提供统一指导,这些信号对于提供出色的网络用户体验至关重要。
网站所有者要想了解他们提供给用户的体验质量,并非需要成为性能专家。Web 指标计划为了简化场景,帮助网站专注于最重要的指标,即核心 Web 指标(LCP FID CLS)。
根据官方的说法,核心 Web 指标 是长期下来根据大量使用者体验所制定的指标。在这之前,Google 已针对使用者体验设置过多种评分机制,但都未真正的搔到使用者的痒处。而在推出全新的 核心 Web 指标 后 Google 甚至提到,若 75% 以上的使用者在网站中的浏览体验都能够通过以上 3 种指标(LCP FID CLS),就能够大幅的提升使用者的搜寻体验,甚至能够让原本因等待而离开的使用者减少 **24%**!
LCP: Largest Contentful Paint 最大内容绘制
good (2.5s)Needs IMPROVEMENT(4s)POOR
FID:First Input Delay 首次输入延迟
good (100ms)Needs IMPROVEMENT(300ms)POOR
CLS:Cumulative Layout Shift 累积布局偏移
good (0.1s)Needs IMPROVEMENT(0.25s)POOR
八、错误信息收集
try / catch
认识 try catch 方案
1 | |
这种方式需要开发者对预估有错误风险的代码进行包裹,这个包裹过程可以手动添加,也可以通过自动化工具或类库完成。自动化方案的基本原理是 AST 技术:比如 UglifyJS 就提供操作 AST 的 API,我们可以对每个函数添加 try catch
try catch 方案的局限性
但是 try catch 处理异常的能力有限,对于运行时非异步错误,它并没有问题。但是对于:
- 语法错误
- 异步错误
try catch 就无法 cover 了。我们来看一个运行时非异步错误:
1 | |
可以被 try catch 处理。但是,将上述代码改动为语法错误:
1 | |
就无法捕获。
我们再看一下异步的情况:
1 | |
也无法捕获(Uncaught ReferenceError:a is not defined)
总结一下, try catch 能力有限,且对于代码的侵入性较强。
window.onerror
我们再看一下 window.onerror 对错误进行处理的方案:开发者只需要给 window 添加 onerror 事件监听,同时 注意需要将 window.onerror 放在所有脚本之前,这样才能对语法异常和运行异常进行处理。
1 | |
这里的参数较为重要,包含稍后需要上传的信息:
- mesage 为错误信息提示
- source 为错误脚本地址
- lineno 为错误的代码所在行号
- colno 为错误的代码所在列号
- error 为错误的对象信息,比如 error.stack 获取错误的堆栈信息
window.onerror 这种方式对代码侵入性较小,也就不必涉及 AST 自动插入脚本。除了对语法错误和网络错误(因为 网络请求异常不会事件冒泡 )无能为力以外,无论是异步还是非异步,onerror 都能捕获到运行时错误。
但是需要注意的是,如果想使用 window.onerror 函数消化错误,需要显示返回 true,以保证错误不会向上抛出,控制台也就不会看到一堆错误提示。
跨域脚本的错误处理
千万不要以为掌握了这些,就万事大吉了。现实场景多种多样,比如 一种情况是:加载不同域的 JavaScript 脚本 ,这样的场景较为常见,比如加载第三方内容,以展示广告,进行性能测试、错误统计,或者想用第三方服务等。
对于不同域的 JavaScript 文件,window.onerror 不能保证获取有效信息。由于安全原因,不同浏览器返回的错误信息参数可能并不一致。比如,跨域之后 window.onerror 在很多浏览器中是无法捕获异常信息的,要统一返回 Script error,这就需要 script 脚本设置为:crossorigin="anonymous"
同时服务器添加 Access-Control-Allow-Origin 以指定允许哪些域的请求访问。
使用 source map 进行错误还原
到目前为止,我们已经学习了获取错误信息的“十八般武艺”。但是,如果错误脚本是经过压缩的,那么纵使你有千般本领,也无用武之地了,因为这样捕获到的错误信息的位置(行列号)就会出现较大偏差,错误代码也经过压缩而难以辨认。这时候就需要启用 source map。很多构建工具都支持 source map,比如我们利用 webpack 打包压缩生成的一份对应脚本的 map 文件进行追踪,在 webpack 中开启 source map 功能:
1 | |
对 Promise 错误处理
我们再来看一下针对 Promise 的错误收集与处理 。我们都提倡养成写 Promise 的时候最后写上 catch 函数的习惯。ESLint 插件 eslint-plugin-promise 会帮我们完成这项工作,使用规则:catch-or-return 来保障代码中所有的 promise(被显式返回的除外)都有相应的 catch 处理。
处理网络加载错误
前面介绍的处理方式都是对已经在浏览器端的脚本逻辑错误进行的,我们设想用 script 标签,link 标签进行脚本或者其他资源加载时,由于某种原因(可能是服务器错误,也可能是网络不稳定),导致了脚本请求失败,网络加载错误。
1 | |
为了捕获这些加载异常,我们可以:
1 | |
除此之外,也可以使用 window.addEventListener(‘error’) 方式对加载异常进行处理,注意这时候我们无法使用 window.onerror 进行处理, 因为 window.onerror 事件是通过事件冒泡获取 error 信息的,而网络加载错误是不会进行事件冒泡的。
这里多提一下, 不支持冒泡的事件还有 :鼠标聚焦 / 失焦(focus / blur)、鼠标移动相关事件(mouseleave / mouseenter)、一些 UI 事件(如 scroll、resize 等)。
因此,我们也就知道 window.addEventListener 不同于 window.onerror,它通过事件捕获获取 error 信息,从而可以对网络资源的加载异常进行处理:
1 | |
那么,怎么区分网络资源加载错误和其他一般错误呢 ?这里有个小技巧,普通错误的 error 对象中会有一个 error.message 属性,表示错误信息,而资源加载错误对应的 error 对象却没有,因此可以根据下面代码进行判断:
1 | |
但是,也因为没有 error.message 属性,我们也就没有额外信息获取具体加载的错误细节,现阶段也无法具体区分加载的错误类别:比如是 404 资源不存在还是服务端错误等,只能配合后端日志进行排查。
到这里,我们简单做一个总结,分析 window.onerror 和 window.addEventListener(‘error’) 的区别。
- window.onerror 需要进行函数赋值:
window.onerror = function() {//...},因此重复声明后会被替换,后续赋值会覆盖之前的值。这是一个弊端。 - 而 window.addEventListener(‘error’) 可以绑定多个回调函数,按照绑定顺序依次执行
更多请参考:https://fe.mbear.top/xing-neng-you-hua/032-xing-neng-jian-kong-he-cuo-wu-shou-ji-yu-shang-bao-xia